ハイブリッドクラウドで大規模なAI推論を実行
-
RobloxのAI利用範囲、特に生成AIの利用はこの数年で急速に拡大しています。
-
このレベルのAIツール使用を支えるインフラの構築と最適化について、3フェイズのうち最終段階に到達しています。
-
大規模な機械学習推論を支えるハイブリッドなクラウド基盤を構築するためどのようなステップを踏んできたかここで紹介したいと思います。
先週のRDCでお知らせしたAIに関する最新の試験プロジェクトは、マルチモーダルな3Dベースモデルを開発してAI生成による制作を促進するためのものです。 世界の何百万のユーザーが利用するバーチャル3Dプラットフォーム向けのAIを常時起動するには、圧倒的な処理能力が必要とされます。 2023年初頭の時点で、対応可能な機械学習推論パイプラインは50足らずでした。 現在のインフラなら250ほどのパイプラインに対応できます。 2か所のデータセンターや、ハイブリッドなクラウド基盤で千を超えるGPU、何万ものCPUを稼働させてモデル全体を運用するのです。 現在その実現に向けて作業中です。
私たちの生成AIについての考え方(Robloxのクリエーター向け)、Robloxの安全を守るためのAI活用事例、世界のコミュニケーションを支えるAI翻訳については以前お伝えしました。 これは単なる一例にすぎません。250近くのモデルが完成すれば、Robloxで発生するやり取りのほとんどをAIが支えることになるでしょう。 Robloxに初めて来た人がどのバーチャル空間に参加すべきか決める時も、AIがおすすめと検索システムで助けてくれます。 バーチャル空間を決めて「プレイ」を押したなら、マッチメイキングシステムが最適なサーバーを検出します。
すでに何百万人ものクリエーターがRobloxの生成AIツールを活用できるようになっています。 アシスタントは単純なプロンプトからバーチャル空間の制作を加速させるアクションやスクリプトを生成します。 テクスチャ・素材生成器はオブジェクトの見た目やスタイルを素早く切り替えることができます。 先日アバターの自動設定機能がリリースされました。アバターの作成プロセスを単純化してクリエーターの労力を削減します。4D生成AI時代の幕開けです。 2024年8月時点で、Robloxで公開されたUGCアバターボディの約8%はアバターの自動設定により制作されたものです。
数年間の取り組みを経て、私たちはついに3フェイズのうち最終段階に入りました。 この取り組みは2021年後半から始まりました。 当時Robloxに統合されたAIプラットフォームは存在せず、エンジニアチームは異なるフレームワークを用い独自の小規模な作業環境を作成していました。 アバターマーケットプレイス、ホームページ、検索などの重要な要素を作るチームは特徴量エンジニアリングを個別に構築していました。 一元的な特徴量ストアにデータを格納すれば効率的なのに、その場しのぎの解決に走ったのです。 コアプラットフォームの力を借りずに、各チームがそれぞれ最適化処理を作り推論スケーリングに取り組んでいました。 バラバラの取り組みはただちに改善されるべきでした。一元化されたプラットフォームであればプロセスは合理的になり、全体の効率が高まります。
フェイズ1:機械学習の強力な基盤作り
初期から採用しているのがKubeflowです。ノートブック、パイプライン、オフライン実験、モデルサービングなど機械学習の基礎をなすパッケージ群を利用できます。 特徴量ストアに関しては、当初はサードパーティを活用しました。 Robloxのエンジニアが機械学習を利用しやすくなるように、roblox-mlというPythonライブラリを開発して製品向けにモデルをデプロイしやすくしました。
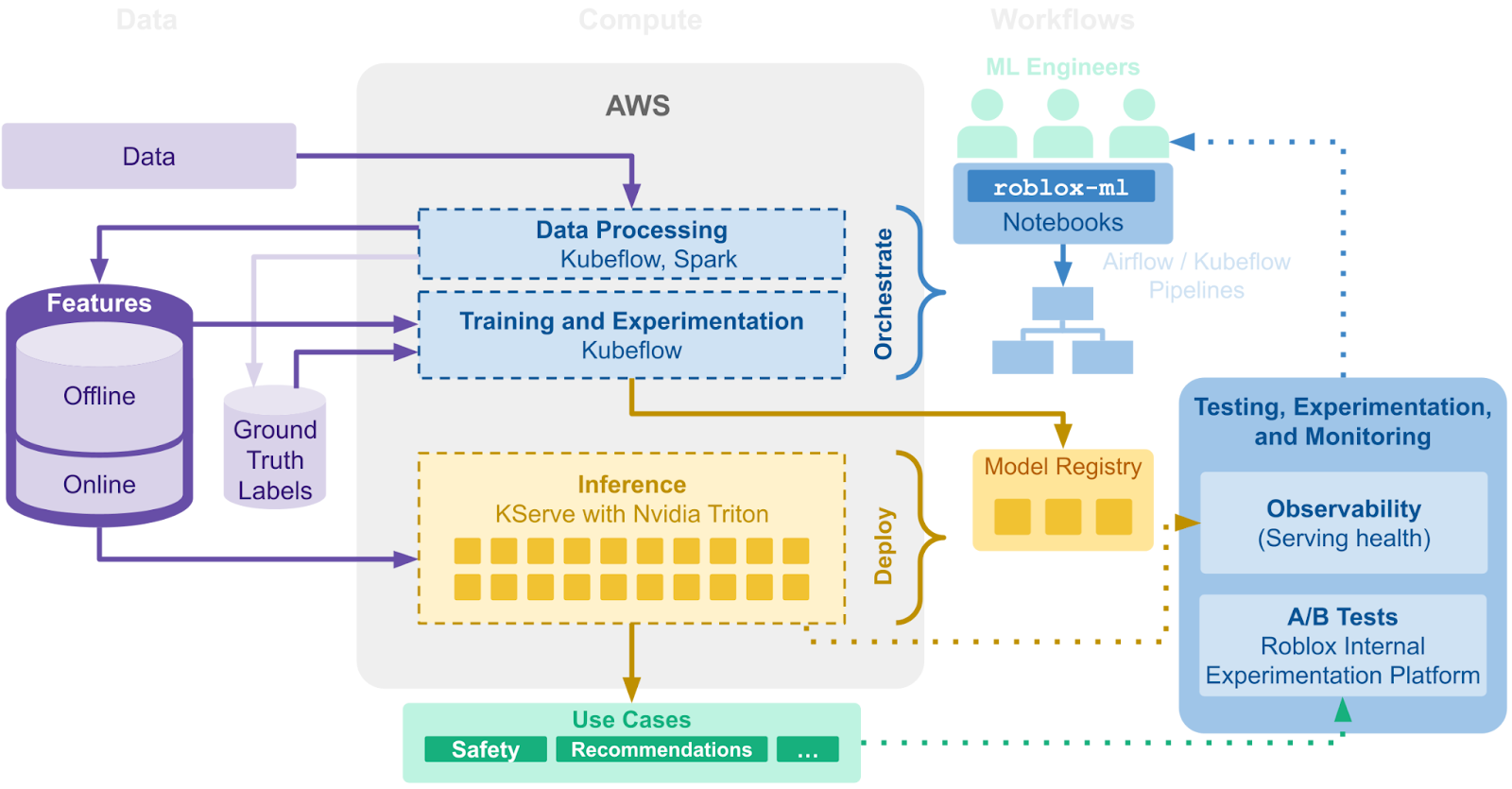
Jupyterノートブックが提供する開発環境はモデルの処理向けに最適化されていて、サーバーはデータアクセスとGPUリソースについて調整されています。 学習処理をスケーリングしたり、モデルの再学習のため定期的に実行するには基本的にパイプラインを書く必要があります。 ここでroblox-mlライブラリが役に立ちます。エンジニアはDockerイメージを作成せずとも、実行環境とソースコードをスナップショットし、優先度つきで計算リソースを選択し、通知や認証情報を設定するだけでノートブックコードをKubeflowパイプラインに変換できます。
特徴量が適切に提供されなければモデルは機能しません。 私たちの特徴量ストアは100を超えるサービスで900以上の特徴量を共有しつつ、新しい特徴量の判別プロセスを単純化します。 これにより特徴量の種類が増えても新モデルをすぐに作成しデプロイできるようになります。
機械学習パイプラインの基盤が整ったところで、オンライン推論に関するサポートの需要が高まりました。パーソナライズや検索、マーケットプレイスがその筆頭です。 バッチ推論は機械学習の運用を成熟させるための中間地点にふさわしいものでしたが、リアルタイム推論のためのモデルレジストリとサービング基盤も開発しました。 モデルレジストリの存在により、Robloxのエンジニアはroblox-mlからモデルをアップロード・ダウンロードできるようになりました。モデルはタグ付けと自動バージョン設定が行われ、追跡とロールバック、A/Bテストが容易になります。 例をあげると、パーソラナイズ用モデルは毎日学習・デプロイさせていて、並行して20ほどのA/Bテストを走らせることもあります。 サービング基盤として使用したのはKServeとTriton Inference Serverです。パフォーマンスに優れたモデルサービング環境で、GPUとCPUを共に使用する機械学習フレームワークにも対応しています。
バッチで運用する場合もオンラインで運用する場合も、モデルのリリース前には綿密なテストを行います。 例えばオフライン実験、シャドウテスト、A/Bテストです。 リリース後もモデルの機能性(推論レイテンシなど)と精度に問題はないかモニタリングが続きます。 安全とマナーにコミットするため、推論結果の不一致が報告された場合は人の手で審査され、重要な判断に間違いがないようにします。モデルの学習用データセットの改善にも役立ちます。
フェイズ2:大規模な推論に備える
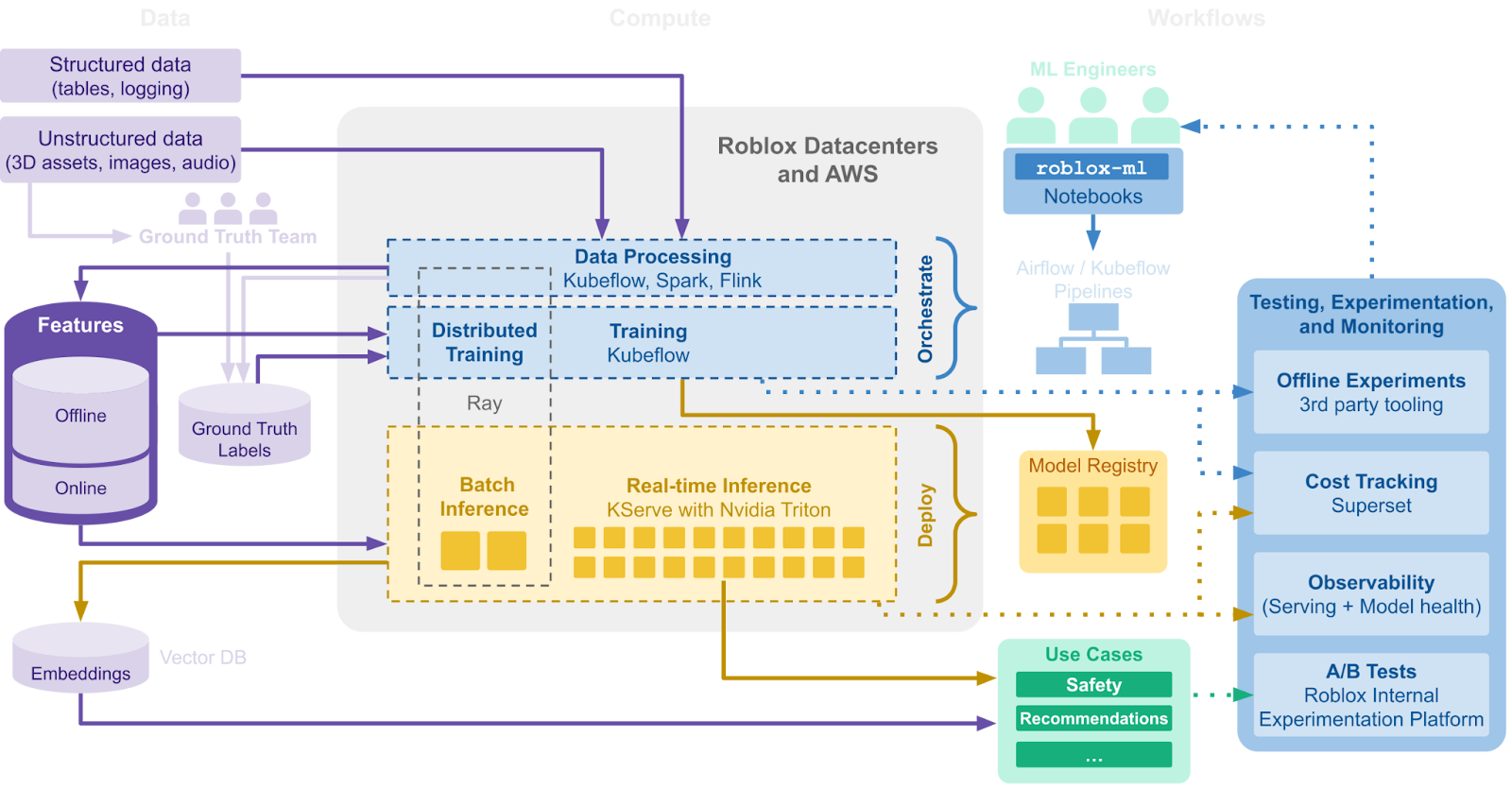
生成AIはRobloxの創造を加速させる存在である — 2023年初頭、私たちはそう確信しました。 AIのポテンシャルを最大限に活用するため、2023年は機械学習の学習・推論インフラの最適化に注力しました。 CLIP埋め込み生成の演算コストはその結果大幅に削減されました。 最初の試みは分散学習システムを拡張することです。複数の作業ノードに何十億ものパラメータがまたがる形でモデルを運用したり、大規模なデータセットの学習を行うためです。
しかし分散型ワークフローの構築を始めてから、既存のオフライン推論向けセットアップでは長期的に予測される成長に対応できないことに気付きました。 初期の設計には、入力と出力が連続で発生するリアルタイム推論を念頭に置いていました。 当初はうまくいっていたものの、並行タスクや多段階のプロセスへの対応は容易ではなく、リソース効率の面でも必要な規模に足りませんでした。 データ分割とエラーハンドリング用の処理をエンジニアが自前で記述する必要もあり、推論規模を広げる場合には時間がかかります。
そこで導入したのがオープンソースの演算フレームワークRay。大量のバッチ推論をこなしやすくなります。 Rayベースの分散タスクパイプラインを構築することで、リソース活用を最適化でき、多段階のプロセスが可能になり、同時並行タスクへの対応能力とエラー耐性も高まりました。 Rayのデータライブラリならストリーミング処理可能なパイプラインを数行のコードで定義できるので、開発スピードが加速します。 バッチ推論にRayを使用することで、これまでに大幅な効率化が実現しています。
引き続き推論を改善させていく必要があったので、CPU推論に関してはすべて自社データセンターに移行させ、レイテンシやプライバシー設定を制御しやすくしました。 2024年6月30日時点で一日あたりのアクティブユーザー数は7950万人。一日に処理するパーソナライズ関連のリクエストは約10億件に上ります。 自社データセンターに処理を移行することで、ユーザーの体験を損なうことなく効率を維持できました。 推論コストの削減のため、多くのシステムはリクエストをキャッシュします。多くのユーザーは一日に何度もRobloxのホームページにアクセスするので、おすすめが古くなってしまうこともありました。 しかし推論の実行場所を最適化し、負荷を分散して計算リソースを節約できるようになったので、効率は改善しました。
規模が拡大するにつれて、あるソリューションが必要になってきました。低遅延・高効率で処理能力に優れ、様々なサービスで素早く処理を繰り返せるカスタム特徴量ストアです。 サードパーティではこの需要を満たせないので、オープンソースプロジェクトFeastを活用して独自のカスタム特徴量ストアを開発しました。 ここではカスタムDSL(ドメイン固有言語)が提供され、バッチ特徴量とストリーミング特徴量の変換を定義できます。 ストリーミング用エンジンとしてはFlinkが採用され、モデルが最新の情報を取り込むために重要なリアルタイム処理が可能になりました。 一方バッチ処理に関しては、分散環境でRobloxのゲームエンジンを再実行することで大量の3Dアセット情報を取得することになります。 私たちの特徴量ストアは一日に300億のデータを取り込み、700億のデータを吐き出します。99%の場合レイテンシは50msで、100以上のサービスに対応しています。
自然言語処理、画像認識、おすすめシステムなど、言語理解の需要が高まったことでモデルの埋め込み使用は急速に拡大しました。 そのため高次元ベクトルの保存・読み込み効率に優れたベクトルデータベースを構築することになりました。 高速な最近傍探索を可能にするベクトルデータベースならマルチモーダル検索やコンテンツ違反の検出にも対応できます。
機械学習モデルを活用するチームが増加するにつれ、計測効率を高めてエンジニアの作業を高速化したいと考えるようになりました。そこでデータ品質を保証するチームが生まれました。 データセット作成パイプラインの設計、人の審査を介したデータの学習と検証、高品質データの送信といった分野でエンジニアを支援するチームです。 データパイプラインの構築やデータセットの検証プロセス、どのデータが送信・追跡・モニターされているかに関するフォーマットの規格化にも貢献しました。
フェイズ3:大規模推論の運用開始
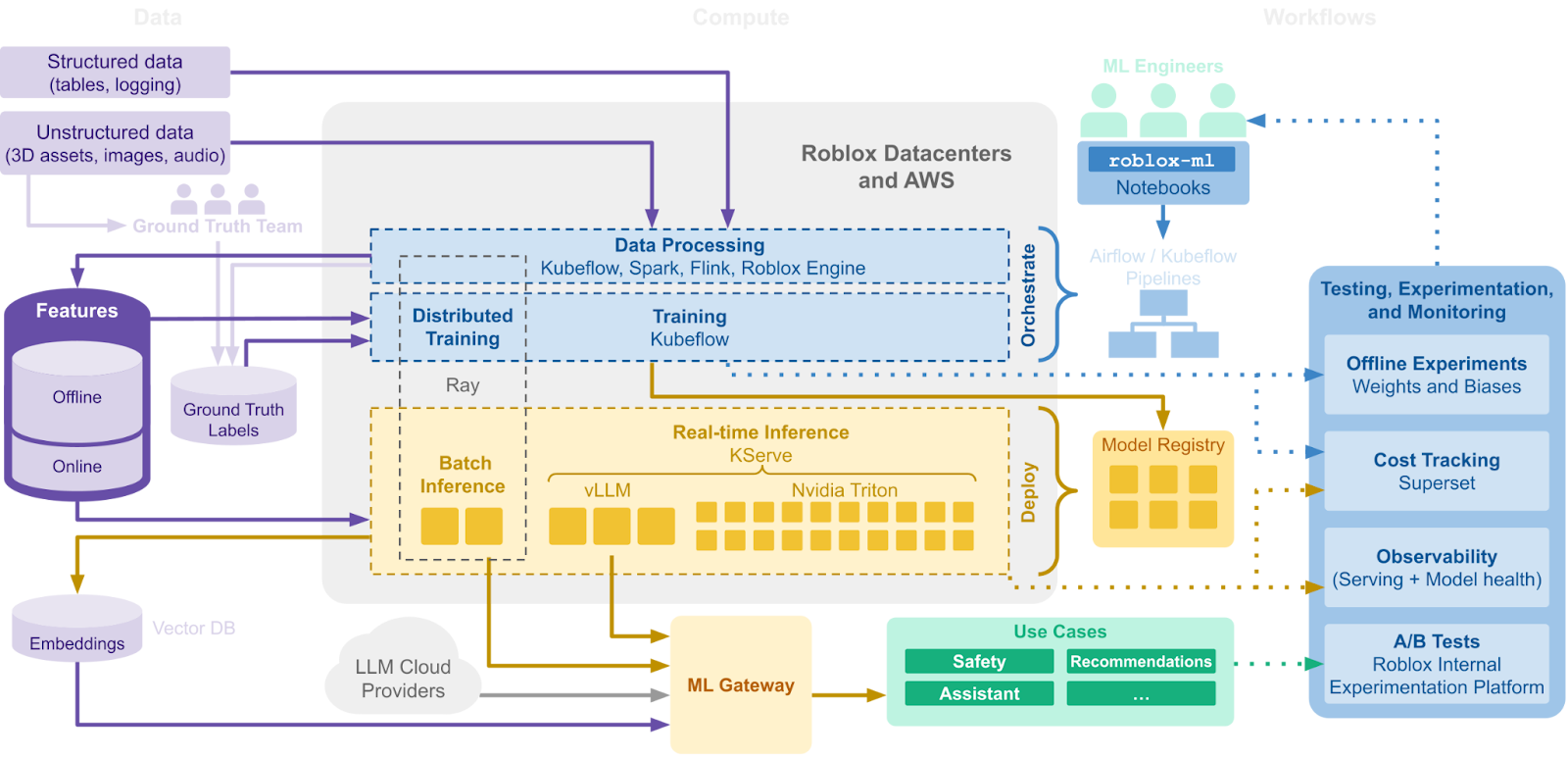
Robloxアシスタントの実装により、週に15億ものトークンが処理されるようになりました。 リアルタイムAIチャット翻訳や音声安全モデル(現在はオープンソース化)といった新機能は大幅に推論パワーの需要を高めました。 AIアプリケーション開発の促進のため二大プロジェクトが開始されました。機械学習ゲートウェイとvLLM projectを基礎とする大規模言語モデル運用(LLMOps)プラットフォームです。 次世代の機械学習を共に支えることになるプロジェクトです。
統合された機械学習ゲートウェイを作成し、各環境における大規模モデルへのアクセスを集約しました。モデルがオープンソースであっても内部開発されたものであっても、CPUやGPUがクラウドにある場合も自社にある場合も同じです。 目標は効率的・合理的なシステムで社内全体のAIリソースを管理することでした。 ゲートウェイはバックエンドに一般的なAPIインターフェース、扱いやすいコンフィグ画面を提供し、デプロイした全モデル間での効率的なリソース共有を可能にします。
さらに生成AIの使用トークン数に基づく集約的なスロットリング、レイテンシを考慮した地域間の負荷分散によって推論サービスの強度を高めました。 また、集約されたAPIキー管理によってセキュリティも向上。総合的なユーザートラッキング機能、モニタリングツールを備え、権限管理機能を組み込むことも可能です。 大規模モデルの使用を最適化してコストを削減できる機能群であり、エンジニアに有益な情報をもたらします。
そして、大規模言語モデル向けの推論エンジンとして採用されたのがvLLM。パフォーマンスに優れ、RobloxのAIアプリケーションを支えてくれます。 vLLMに移行した結果、レイテンシと処理能力はほとんど倍加しました。現在は週に40億トークン近くが処理されています。
数多くのバーチャル空間や巨大なユーザーベースに対応するためには効率が必要とされます。そのため私たちはオープンソースや最新技術を活用していく方針で、vLLMの採用もその一環です。 RobloxはオープンソースのvLLMプロジェクトに積極的に貢献し、vLLMのマルチモーダル対応にあたっては開発を率先しました。マルチモーダル化によりエンジンはテキストだけでなく画像も処理できるようになります。将来的には他のデータにも対応する余地があります。 投機的デコーディングも実装されたことで推論パフォーマンスはさらに向上し、言語タスク処理の速度と効率は高まりました。
機械学習ゲートウェイとvLLMが数百の機械学習パイプラインを効率的に支えてくれます。AIベースの機能の需要は高まる一方ですが、様々な場面で推論を利用できるようになるのです。 そして、この仕事はまだまだ終わっていません。 RobloxにおけるAIの未来について、壮大なプランがあります。 初心者から熟練者までクリエーターの制作を効率化できるAIベースの新ツールを開発中です。 これまで通り、インフラの能率向上も目指しています。皆が毎日AIツールを使えるようにするためです。
オープンソース主義
ここまで来るためにオープンソースプロジェクトの力を借りてきました。 多くの技術スタックは、上記のようなオープンソース技術の上に作られています。
RobloxはオープンソースAIコミュニティの心強いパートナーとなることを目指し、独自のオープンソース技術による貢献も果たしています。 Roblox初となるオープンソースモデル、音声安全チェッカーが先日公開されました。機械学習ゲートウェイについてもオープンソース化を目指しています。 コミュニティの一員として活躍できることは光栄です。AIの未来にはオープンで透明であることが求められています。