



Açık Kaynak Sesli Sohbet Güvenliği Modelimize Daha Fazla Dil Ekliyoruz
-
Parametrelerini 94.600'den 120.200'e çıkararak ve yedi dil daha ekleyerek açık kaynak sesli sohbet güvenliği sınıflandırıcımızı güncelliyoruz.
-
Sınıflandırıcının ilk sürümünden bu yana İngilizce sesli sohbet verilerinde %1'lik bir sahte pozitif oranıyla doğruluğu %59,1'e çıkardık. Bu, önceki sürümün %30,9'luk geri çağırma oranına göre %92'lik bir gelişme.
Güvenliği ve uygar davranışı teşvik etmek her zaman Roblox'ta yaptığımız her işin temelini oluşturmuştur. Güçlü güvenlik sistemleri oluşturmaya yaklaşık yirmi yılımızı verdik. Yeni teknolojiler kullanıma sunuldukça bunları sürekli geliştiriyor ve büyütüyoruz. 2024'te ebeveyn denetimlerini yenileme dâhil olmak üzere güvenlik alanında 40'tan fazla iyileştirme yayımladık. Bu iyileştirmeyi bugün yeniden güncelliyoruz. Ayrıca sektördeki ilk açık kaynak sesli sohbet güvenlik sınıflandırıcıyı kullanıma sunduk. Bu araç, 23.000 kereden fazla indirildi. Bugün, daha da doğru olan ve daha fazla dilde çalışan güncellenmiş bir sürüm yayımlıyoruz.
Bu sınıflandırıcı da dâhil olmak üzere kullanıcılarımızı korumaya yardımcı olan güvenlik sistemlerinin çoğu yapay zekâ modelleri tarafından desteklenmektedir. Bunlardan bazılarını açık kaynak olarak sunuyoruz çünkü yapay zekâyla güvenlikteki gelişmeleri paylaşmanın tüm sektörümüze fayda sağladığını biliyoruz. Bu nedenle yakın zamanda kurucu ortak olarak ROOST'a katıldık. Kâr amacı gütmeyen bu kuruluş, açık kaynak güvenlik araçlarını teşvik ederek dijital güvenliğin önemli alanlarına sorunları çözerek katkıda bulunmaya kendini adamıştır.
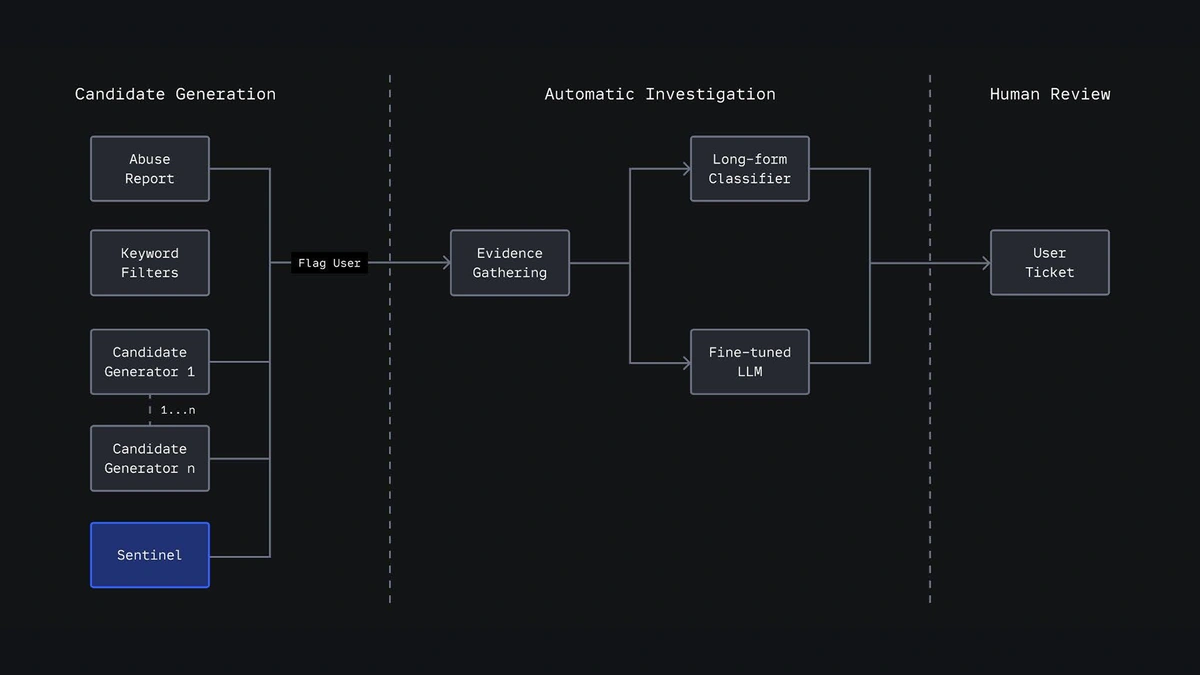
Platformumuzda her gün dünyanın dört bir yanında gerçekleşen içerik ve etkileşim hacmini yönetirken yapay zekâ, kullanıcıların güvenliğini korumak için önemli bir unsurdur. Oluşturduğumuz modellerin ihtiyaçlarımızı karşılamaya yardımcı olduğundan eminiz. Örneğin 2024'ün dördüncü çeyreğinde Roblox kullanıcıları 300 milyar adet içerik yükledi. Bu milyarlarca video, ses, metin, sesli sohbet, avatar ve 3D deneyimin yalnızca %0,01'inin politikalarımızın ihlalini içerdiği tespit edildi. Politikalara aykırı olan bu içeriğin de neredeyse tamamı, otomatik ön taramada daha kullanıcılar görmeden saptanıp kaldırıldı.
Sesli sohbet güvenliği sınıflandırıcımızın açık kaynak sürümünü, daha doğru hâle getirmek ve içeriği daha fazla dilde denetlememize yardımcı olmak için güncelledik. Yeni model:
-
Çok dilli verilerle ilgili eğitim sayesinde ihlalleri yedi dilde (İspanyolca, Almanca, Fransızca, Portekizce, İtalyanca, Korece ve Japonca) tespit eder.
-
Düşük sahte pozitif oranları ile önceki sürümde %30,9'luk geri çağırma oranına göre %92'lik bir gelişme olan %59,1'lik genel geri çağırma oranına sahiptir.
-
Geniş ölçekte hizmet verecek şekilde optimize edilmiştir ve en yüksek noktada saniyede 8.300 isteğe (çoğu ihlal içermeyen) hizmet vermektedir.
İlk modelin piyasaya sürülmesinden bu yana ABD'deki kullanıcılar arasında kötüye kullanım bildirim oranlarının, sesli sohbet yapılan her saat için %50'den fazla azaldığını gördük. Bu araç ayrıca günde milyonlarca dakikalık sesli sohbeti insan denetimcilerden daha isabetli biçimdedenetlememize yardımcı oldu. Güvenlik sistemlerimizi geliştirmekten asla vazgeçmiyoruz ve açık kaynak sürümünü de güncellemeye devam edeceğiz.
Verimli Çok Dilli Sesli Sohbet Güvenliği Sınıflandırıcısı
İlk açık kaynaklı sesli sohbet güvenliği sınıflandırıcımız, makine etiketli İngilizce sesli sohbet ses örnekleriyle ince ayar yapılmış bir WavLM base+ modeline dayanıyordu. Bu uçtan uca mimarinin cesaret verici sonuçları, özelleştirilmiş bir mimari ile daha fazla deney yapılmasına yol açtı. Modelin karmaşıklığını ve doğruluğunu optimize etmek için bilgi damıtma kullandık, bu da büyük ölçekli çıkarım hizmeti için caziptir. Yeni sınıflandırıcımız, bu temel yapı taşlarını kullanır ve veri kullanımı ve mimari iyileştirmelerindeki çalışmaları ölçeklendirip genişletir.
Çok dilli verilerle ilgili eğitim, tek sınıflandırıcı modelimizin desteklenen ilk sekiz dilimizden herhangi birinde sorunsuz çalışmasını sağlar. Eğitime yönelik iyileştirmelerimiz, modelin ilk sürüme göre tipik bir çıkarım senaryosunda hem daha doğru hem de %20 ila %30 daha hızlı çalıştığı anlamına geliyor.
Yeni ses güvenliği sınıflandırıcısı hâlâ WavLM mimarisine dayanmaktadır ancak katman yapılandırması önceki sürümden ve önceden eğitilmiş WavLM modellerinden farklıdır. Özellikle transformatör katmanlarının iç zaman çözünürlüğünü azaltmak için ek bir evrişim katmanı ekledik. In total, our new model architecture has 120.2 million parameters, an increase of 27% compared with 94.6 million in the previous version. Bu artışa rağmen, yeni model 4 ila 15 saniyelik girdi segmentleriyle kullanıldığında hesaplama süresi %20 ila %30 azalır. Bu, modelin giriş sinyalini öncekinden daha kısa bir gösterime sıkıştırması sayesinde mümkün olmuştur.
Çeşitli Etiketleme Stratejilerinden Yararlanma
Uçtan uca bir modelin denetimli eğitimi, özenle seçilmiş ses ve sınıf etiketi çiftleri gerektirir. Sabit bir etiketli veri akışı sağlayan veri hattımızda önemli iyileştirmeler yaptık. Eğitim nesnesinin temeli, desteklenen dilleri içeren 100.000 saatten fazla konuşmadan oluşmuş, makine tarafından etiketlenen büyük bir veri kümesidir. Konuşmayı otomatik olarak yazıya döktük ve istenen politika ve zarar verici iletişim kategorilerini paylaşan şirket içi metin tabanlı zararlılık sınıflandırıcımızdan geçirdik. Veri toplama, uç vakaları ve daha az yaygın politika ihlallerini daha iyi yakalamak için zararsız konuşmalardan daha yüksek bir olasılıkla kötü niyetli içeriği örneklemektedir.
Konuşma dökümlerine ve metin tabanlı sınıflandırmaya dayalı etiketler, sesli sohbet içeriğinde gözlemlenen nüansları tam olarak yakalayamaz. Bu nedenle, önceki eğitim aşamasında kullanılan modele ince ayar yapmak için insanlar tarafından etiketlenmiş verileri kullandık. Sınıflandırma görevi aynı olsa da ikinci eğitim aşaması karar sınırlarını iyileştirmeye ve sesli sohbete özgü ifadelere duyarlılığı vurgulamaya yardımcı olur. Bu, insan etiketli değerli örneklerden maksimum düzeyde yararlanmamıza elveren bir müfredat öğrenme şeklidir.
Uçtan uca model eğitimi ile ilgili bir zorluk, etiketleme politikasının zaman içinde değişmesi durumunda hedef etiketlerin geçersiz hâle gelebilmesidir. Bu nedenle, kabul edilebilir ses politikamızı geliştirirken, eski etiketleme standartlarını kullanan veriler için özel işlemlere ihtiyaç olur. Bunun için modelin mevcut sesli sohbet politikasına uymayan veri setlerinden öğrenmesini sağlayan çok görevli bir yaklaşım kullandık. Bu, eski politikanın ayrı bir başlıkla sınıflandırılmasını içerir ve model gövdesinin hedeflenen etiketleri veya birincil başlığı etkilemeden eski veri setinden öğrenmesini sağlar.
Daha Kolay Dağıtıma Göre Kalibre Edilmiş Bir Model
Sınıflandırma modelini kullanmak, çalışma noktasına karar vermeyi ve sınıflandırıcı hassasiyetini görev gereksinimlerine göre eşleştirmeyi gerektirir. Model dağıtımını kolaylaştırmak için model çıktılarını kalibre ettik ve sesli sohbet denetimine göre ayarladık. Tutulan bir veri setinden parçalı doğrusal dönüşümleri tahmin ettik, bunu her çıktı kafası ve desteklenen dil için ayrı ayrı yaptık. Bu dönüşümler, nihai modelin doğal olarak kalibre edilmesini sağlayan model damıtma sırasında uygulanmıştır. Bu, çıkarım sırasında süreç sonrası işlemleri ortadan kaldırmıştır.
Bu yeni açık kaynak modeli toplulukla paylaşmaktan heyecan duyuyoruz ve gelecekteki güncellemeleri de gerçekleştikçe paylaşmayı umuyoruz.