在混合雲中大規模執行 AI 推論
-
過去幾年來,Roblox 使用 AI(特別是生成式 AI)的領域快速成長。
-
我們正在進行三階段流程的最後階段,目標是打造及最佳化支援這種層級的 AI 工具所需要的基礎架構。
-
本文將公開我們為了打造能大規模支援 ML 推論的混合雲基礎架構所採取的措施。
在上週的 RDC 上,我們發表了最新的 AI 培育專案:開發一個多模態的 3D 基礎模型來推動生成式創作。 要在一個擁有數百萬名用戶、永不停機的沉浸式 3D 全球平台上支援 AI,需要巨量的運算能力。 在 2023 年初,我們支援的機器學習 (ML) 推論管線不到 50 個。 現在,我們的基礎架構可支援大約 250 個這類管線。 我們有兩個資料中心和混合雲基礎設施,維護數以萬計的 CPU 和超過一千個 GPU 來執行這些模型。 而我們並不打算止步於此。
我們先前分享了我們關於生成式 AI 如何造福創作者的看法、如何使用 AI 確保 Roblox 的使用者安全,以及 AI 翻譯如何協助世界各地的人們溝通。 不過那些只是一些範例;目前生產環境中的模型約有 250 個,Roblox 上幾乎所有的互動都有某種形式的 AI 在支援。 當使用者第一次進入 Roblox 並查看要加入哪個體驗時,我們的推薦和搜尋系統就已經有 AI 在運作。 而當這位使用者選擇體驗並按下遊玩按鈕時,我們的配對演算法會找出最適合加入的伺服器。
數以百萬的創作者現在就已可利用我們生成式 AI 工具的強大功能。 透過 Assistant 協助,創作者可以使用簡單的提示來生成指令碼和動作來協助加速創作體驗。 使用我們的紋理和材質產生工具,創作者可以快速對物件的外觀和風格進行變更及改版。 而現在我們將進入 4D 生成式 AI 的時代,包含最近推出的虛擬人偶自動設定功能,可簡化建立虛擬人偶的流程,為創作者省下數小時的工作時間。 截至 2024 年 8 月,在 Roblox 上發布的 UGC 虛擬人偶身體大約有 8% 使用虛擬人偶自動設定。
我們正進入已經持續數年的三階段流程之最後階段。 這趟旅程開始於 2021 年末, 當時由於缺乏統一的 Roblox AI 平台,因此各工程團隊分別建立了自己的迷你平台並選擇了各種不同架構。 我們看到各團隊開發出重要的元件,包括虛擬人偶市集、首頁,還有搜尋功能,每個部分都在建立自己專用的特徵工程。 團隊並沒有利用集中化的特徵庫,而是拼湊各種臨時方案。 此外,每個團隊都需要獨力開發自己的最佳化方案,並解決擴展推論的挑戰,而沒有核心平台的支援。 這種零碎化的方式凸顯了建立一個統一集中平台的迫切需求,以簡化流程並全面提升效率。
第一階段:打造 ML 的堅強基礎
我們很早就採用 Kubeflow 以利用它的成套 ML 核心建構模組,包括 Notebook、管線、離線實驗和模型服務。 我們仍然需要特徵庫,因此我們採用了第三方解決方案來起步。 為了讓 Roblox 的工程師更容易使用 ML,我們開發了 roblox-ml,這個 Python 函式庫能夠進一步減少將模型部署到生產環境的複雜度。
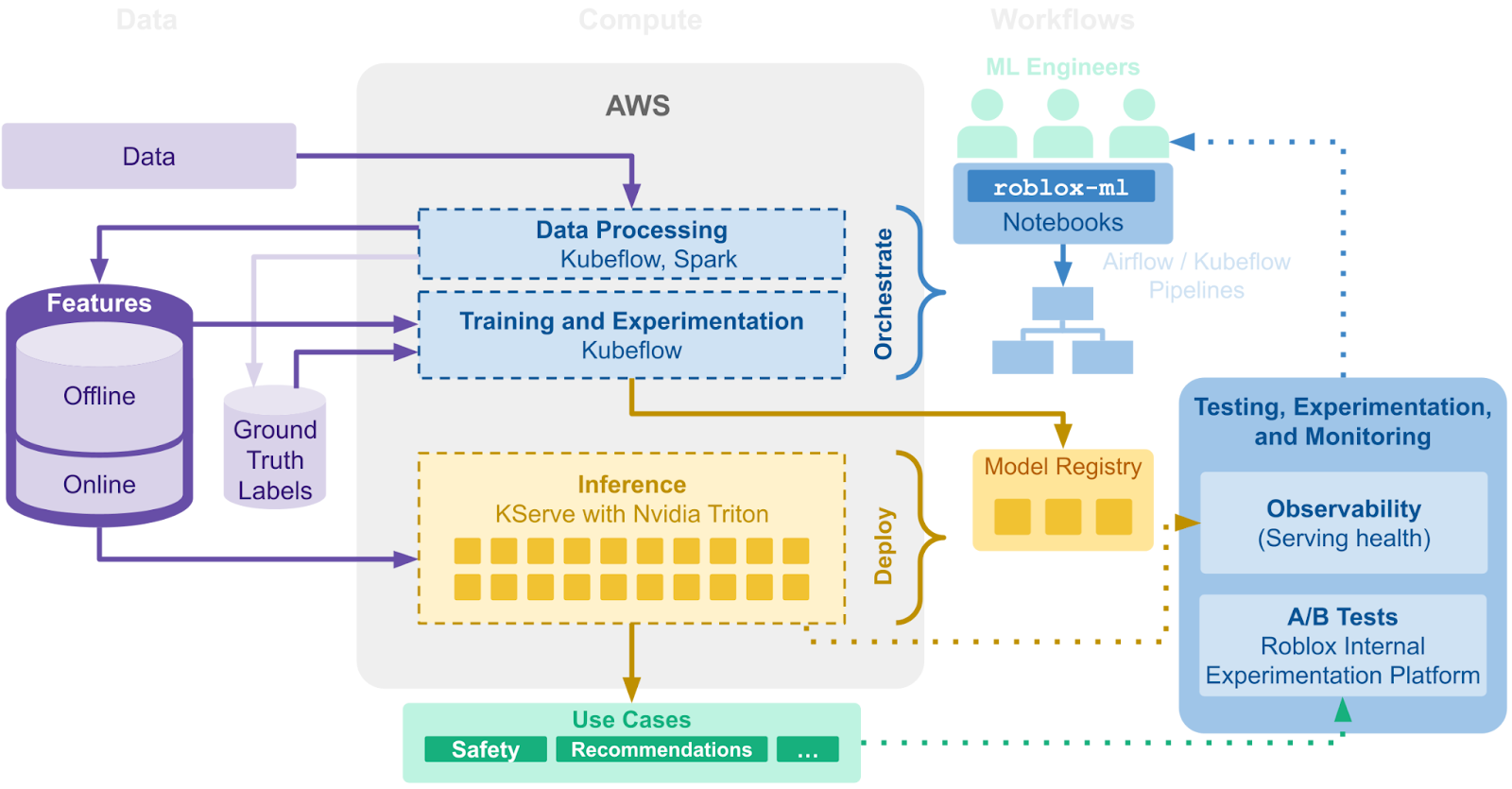
我們使用了 Jupyter Notebook 提供模型迭代的最佳化開發環境,搭配伺服器設定提供必要的資料存取權和 GPU 資源。 要擴大訓練工作或定期執行以重新訓練模型,以往通常需要編寫管線。 我們的 roblox-ml 函式庫可讓工程師為執行階段環境和原始碼建立快照,而不需要建置 Docker 映像,並透過選擇優先運算資源、設定通知和處理驗證,輕鬆將 Notebook 程式碼轉換成 Kubeflow 管線。
模型必須在正確的時間具備正確的特徵才有效。 我們的特徵庫簡化了定義新特徵的程序,同時促進在超過 100 個特徵服務中共用超過 900 個特徵。 這讓各團隊能夠在我們的特徵總數成長的同時,更快速地建立和部署新模型。
我們的 ML 管線平台正常運作並穩定後,我們觀察到線上推論支援的需求逐漸成長,當中以個人化、搜尋和市集為主。 雖然我們建議以批次推論作為邁向成熟 ML 營運的中途點,不過我們也開發了模型登錄和服務平台來支援即時推論。 Roblox 工程師可透過我們的模型登錄來使用 roblox-ml 上傳及下載模型,模型會附有標記並自動進行版本管理,以便追溯、回溯和 A/B 測試。 舉例來說,我們的個人化模型每天都會訓練及部署,並且經常平行執行約 20 個 A/B 測試。 服務平台方面,我們使用 KServe 搭配 Triton 推論伺服器作為基礎模型提供執行階段服務,因為它擁有強大的效能,並支援同時使用 GPU 和 CPU 的多重 ML 架構。
無論是批次運作或線上運作,Roblox 的模型在推出前都會經過大規模的測試。 這包含離線測試、影子測試和 A/B 測試。 在推出之後,模型會繼續受到監控,確保它們在運作(例如推論延遲)和準確度上都達到預期效能。 為了實踐我們對安全和禮儀的承諾,真人審核人員也會評估任何回報的推論不一致,協助確保我們的關鍵決策正確無誤,並有助於改善模型的訓練資料集。
第二階段:準備擴大推論
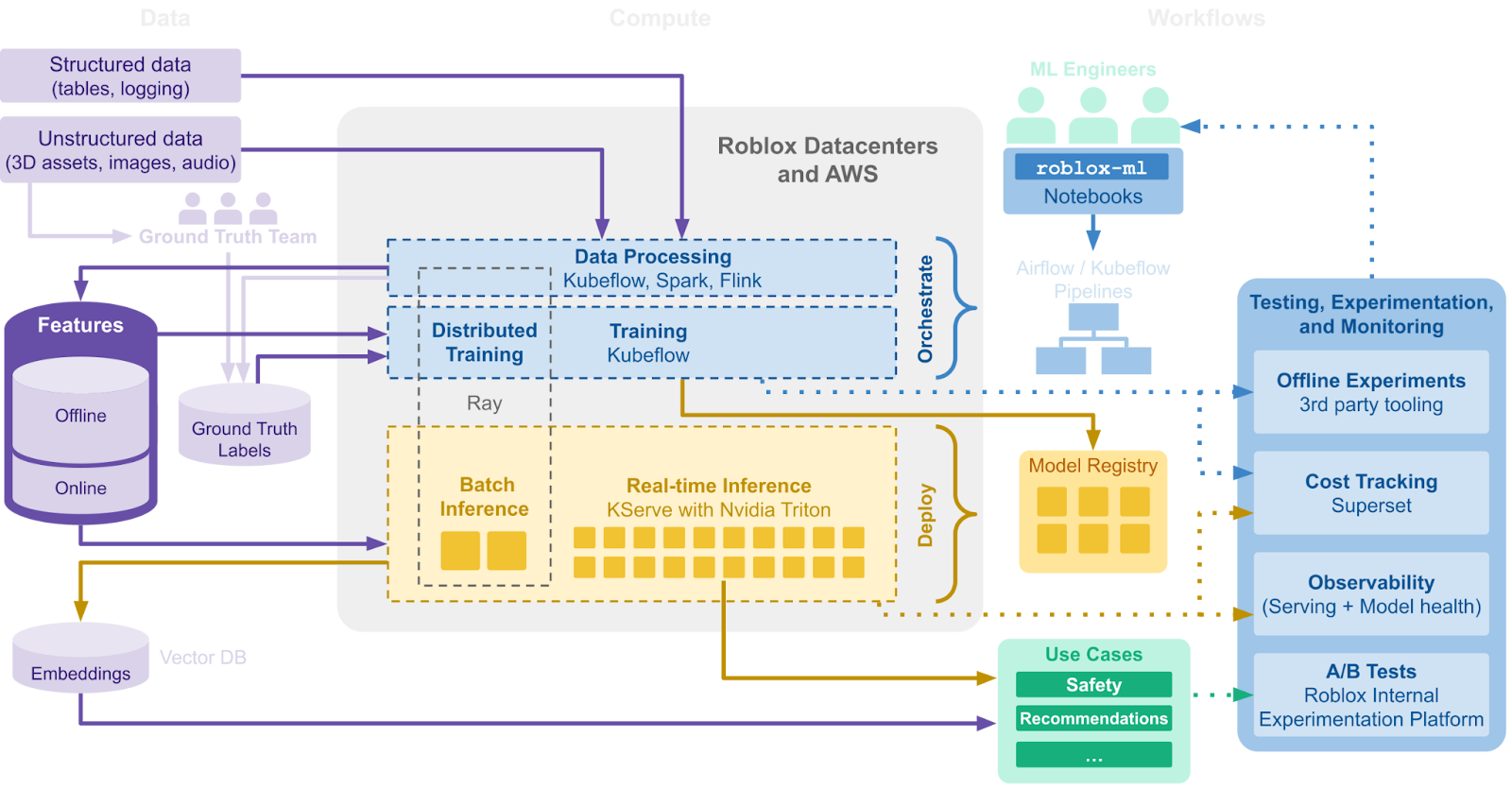
2023 年初,我們看見了生成式 AI 加速 Roblox 上創作活動的巨大潛力。 為了充分發揮這份潛力,我們 2023 年大部分時間都在最佳化 ML 訓練與推論基礎架構的效能與效率。 歸功於這些最佳化,我們大幅減少了建立 CLIP 嵌入需要的運算成本。 首先,我們擴充了自己的分散式訓練系統,以利用大型資料集訓練,並在多個工作節點上執行含有數十億個參數的模型。
隨著我們開始建置分散式工作流程,我們意識到現有的離線推論設定將無法支援我們觀察到的長期成長率。 我們的初始設定是針對即時推論所設計,亦即輸入和輸出資料是有連續性的。 雖然這在我們的開發階段初期成效良好,但並不易支援平行工作或多階段處理,資源效率也不足以支援我們現在需要的規模。 此外,工程師也需要撰寫自己的資料分塊和錯誤處理邏輯,隨著我們的推論需求提升,耗費的時間也逐漸增加。
為了應對這些挑戰,我們新增對 Ray 的支援,這是開放原始碼的運算架構,能更輕鬆擴大批次推論的工作負載。 建構出適用於批次推論的 Ray 分散式工作管線後,我們得以最佳化資源利用、實現多階段處理,並提供穩健的平行工作和更寬大的容錯率。 此外,Ray Data 函式庫讓工程師使用幾行程式碼即可定義具備串流處理的管線,有助於開發人員加快速度和效率。 使用 Ray 進行批次推論到目前為止,我們已看到巨大的效率提升。
由於我們的推論需求持續成長,我們將所有 CPU 推論移至自家的資料中心,這讓我們對於延遲和隱私設定有更直接的控制權。 我們為 7950 萬名每日活躍使用者(截至 2024 年 6 月 30 日為止)每天處理約 10 億個個人化要求。 將這項工作負載移至我們自家的資料中心有助於維持效率,而不會損及使用者體驗。 為了節省推論成本,許多系統會為要求儲存快取;原本這會導致推薦內容過時,因為有許多使用者一天會造訪 Roblox 首頁數次。 這項移動也改善了我們的效率,讓我們能夠更有效最佳化執行推論的位置,並分配工作負載以減少需要的運算資源。
隨著我們持續擴展,我們意識到需要自訂一套特徵庫解決方案,以支援高輸送量、低延遲,且符合成本效益,同時還能實現各種服務的快速迭代。 現有的第三方解決方案並不符合這些需求,因此我們開發了自己的自訂特徵庫,以開放原始碼專案 Feast 為基礎打造。 我們的特徵庫提供自訂的特定領域語言,可用於定義批次處理和串流處理特徵的轉換。 我們採用 Flink 作為串流處理引擎來實現即時特徵,這對於需要盡可能整合最新資訊的模型至關重要。 在光譜的另一端,則是需要在分散式環境中重新執行 Roblox 遊戲引擎,以批次方式處理大量 3D 素材所衍生出的特徵。 我們的特徵庫現在每天會擷取約 300 億條記錄,並提供約 700 億條記錄,P99 延遲為 50 毫秒,並支援超過 100 種特徵服務。
無論是透過 NLP、電腦視覺或推薦系統,對於語義理解的需求不斷成長,模型對嵌入的使用也迅速增加。 這促使我們建置一個向量資料庫,以有效地儲存和擷取向量作為高維度點。 向量資料庫實現了快速的最鄰近查詢,以推動多模態搜尋和內容違規偵測等功能。
隨著越來越多團隊開始利用 ML 模型,我們希望能獲得規模效率,並協助工程師更快實現成果,因此我們建立了自己的基準事實團隊。 這個團隊協助工程師設計自己的資料集生產管線、使用真人評估者訓練和驗證資料,並提供高品質資料。 這有助於我們標準化建置資料管線與驗證資料集的流程,以及資料傳遞、追蹤和監控的格式。
第三階段:大型推論營運化
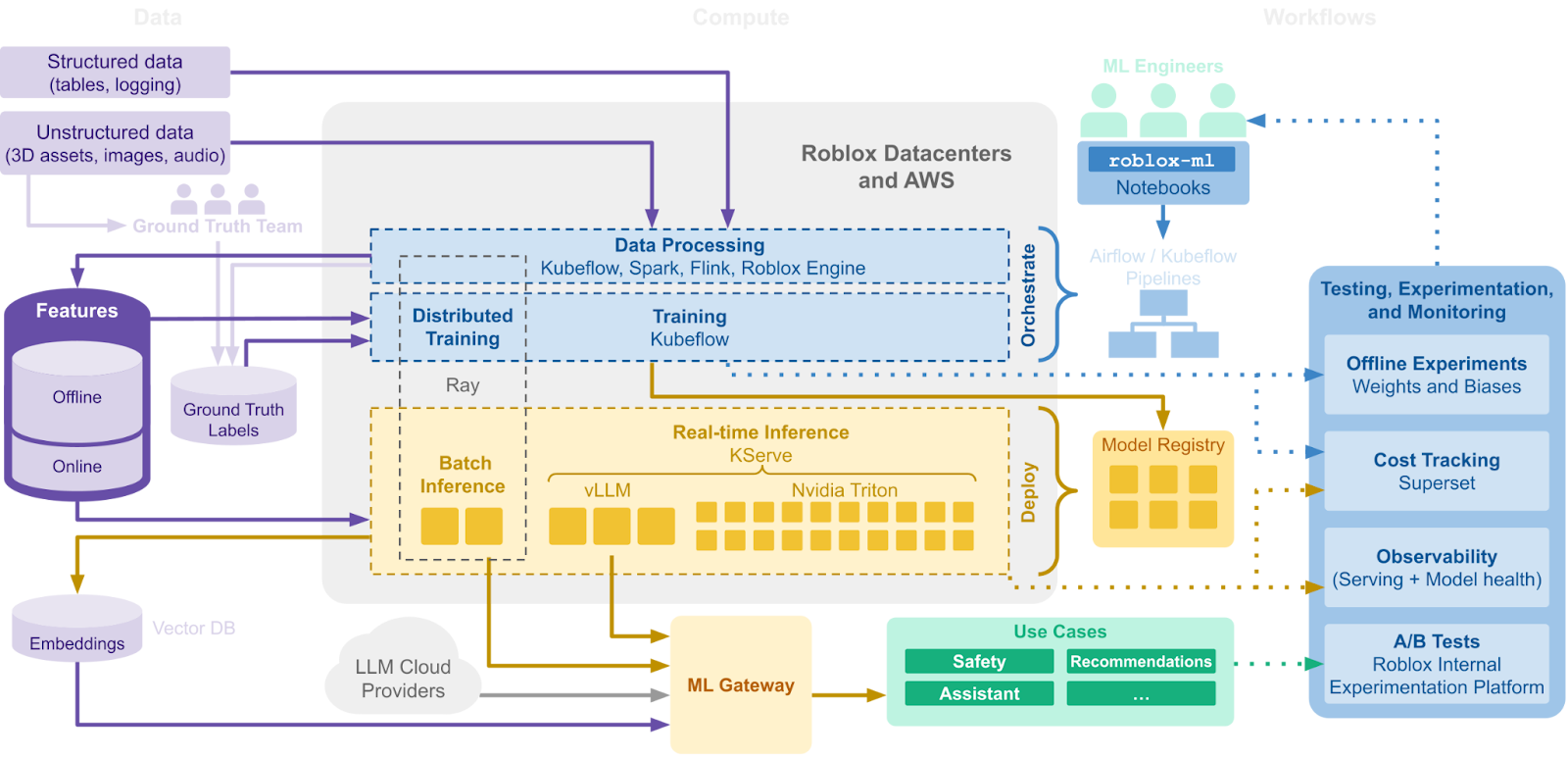
隨著 Roblox Assistant 推出,我們觀察到每週處理的詞元數成長到 15 億。 我們也推出了新功能,包括 即時 AI 聊天翻譯 和我們的 語音安全模型(現在為 開放原始碼),大幅提升了推論處理能力的需求。 我們也展開兩個核心專案來增強 AI 應用程式開發:我們的 ML 閘道,以及一個以 vLLM 專案為中心的大型語言模型營運 (LLMOps) 平台。 這兩個專案結合在一起,將成為 Roblox 下一代 ML 的基礎。
我們打造了統一的 ML 閘道以集中所有大型模型(包含開放原始碼與內部開發)的存取權,且可橫跨各種環境,包含雲端和內部部署中的 CPU 和 GPU。 我們的目標是建立一套有效率且精簡的系統,來管理整個公司的 AI 資源。 在後端,閘道提供共通的 API 介面、對使用者友善的設定選項,以及在我們部署的所有模型間有效率的資源分享。
閘道透過為生成式 AI 工作負載提供以詞元數為標準的集中式節流,以及區域間的延遲感知負載平衡,提升我們推論服務的韌性。 此外,閘道藉由集中化 API 金鑰管理提升了安全性,可進行全面的使用情形追蹤,且可能實作權利機制,並整合監視工具來提高可觀察性。 這些功能都協助我們將大型模型的利用最佳化、減少成本,並且為整個 Roblox 的工程師提供寶貴的見解。
此外,我們採用了 vLLM 作為 LLM 的主要推論引擎,利用 vLLM 的高效能功能來推動整個 Roblox 的 AI 應用程式。 自從移至 vLLM 後,我們在延遲和輸送量方面已看到將近 2 倍的改善,且我們目前每週提供將近 40 億個詞元。
我們選擇 vLLM,體現了我們致力於利用開放原始碼和最新技術,以滿足我們龐大使用者群體以及多樣化體驗的需求。 Roblox 是開放原始碼 vLLM 專案的積極貢獻者,引領著 vLLM 多模態支援的開發,讓引擎不只能處理文字,還能處理圖像,且在未來有可能處理其他類型資料。 我們也實作了推測性解碼技術,以進一步改善推論的效能,讓語言工作的處理更快、更有效率。
藉由 ML 閘道和 vLLM,我們能有效支援 Roblox 各處使用的數百種 ML 管線,並且能針對持續成長的 AI 技術功能需求持續擴充推論規模。 而我們的這項工作還遠未完成。 針對 Roblox 上 AI 的未來,我們有遠大的計畫。 我們正在開發新的 AI 工具,讓新手和專業創作者在創作上更有效率。 一如往常,我們正在努力提高基礎架構的效能與效率,以更有效支援我們和我們的創作者每天使用的 AI 工具。
我們對開放原始碼的堅持
我們能走到今天,有賴幾個成功的開放原始碼專案。 我們的技術組合有許多部分是使用上述的開放原始碼技術打造的。
我們致力於成為開放原始碼 AI 社群堅強的合作夥伴,並貢獻我們自己部分的開放原始碼技術。 我們最近公佈了第一個自製的開放原始碼模型:我們的 語音安全分類器,而我們目前正在打造 ML 閘道,希望能讓該功能也成為開放原始碼項目。 我們相信 AI 的未來應該是開放透明的,也很高興能成為此社群活躍的成員。